From the Hadoop homepage:
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using a simple programming model. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
This plugin will automatically configure the Hadoop framework on your cluster(s). It will also configure dumbo which provides a convenient Python API for writing MapReduce programs in Python as well as useful tools that make it easier to manage HDFS.
See also
Learn more about Hadoop at it’s project page
To use this plugin add a plugin section to your starcluster config file:
[plugin hadoop]
setup_class = starcluster.plugins.hadoop.Hadoop
Next update the PLUGINS setting of one or more of your cluster templates to include the hadoop plugin:
[cluster mycluster]
plugins = hadoop
The next time you start a cluster the hadoop plugin will automatically be executed on all nodes. If you already have a cluster running that didn’t originally have hadoop in its plugin list you can manually run the plugin using:
$ starcluster runplugin hadoop mycluster
StarCluster - (http://star.mit.edu/cluster)
Software Tools for Academics and Researchers (STAR)
Please submit bug reports to starcluster@mit.edu
>>> Running plugin hadoop
>>> Configuring Hadoop...
>>> Adding user myuser to hadoop group
3/3 |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 100%
>>> Installing configuration templates...
3/3 |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 100%
>>> Configuring environment...
3/3 |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 100%
>>> Configuring MapReduce Site...
3/3 |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 100%
>>> Configuring Core Site...
3/3 |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 100%
>>> Configuring HDFS Site...
3/3 |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 100%
>>> Configuring masters file...
3/3 |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 100%
>>> Configuring slaves file...
3/3 |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 100%
>>> Configuring HDFS...
3/3 |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 100%
>>> Configuring dumbo...
3/3 |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 100%
>>> Starting namenode...
>>> Starting secondary namenode...
>>> Starting datanode on master...
>>> Starting datanode on node001...
>>> Starting datanode on node002...
3/3 |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 100%
>>> Starting jobtracker...
>>> Starting tasktracker on master...
>>> Starting tasktracker on node001...
>>> Starting tasktracker on node002...
3/3 |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 100%
>>> Job tracker status: http://ec2-XXXX.compute-1.amazonaws.com:50030
>>> Namenode status: http://ec2-XXXX.compute-1.amazonaws.com:50070
>>> Shutting down threads...
20/20 |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 100%
Once the plugin has completed successfully you should be able to login and begin using HDFS and the Hadoop framework tools. Hadoop’s home directory, where all of the Hadoop jars live, is /usr/lib/hadoop.
If you’d like to change the hadoop temporary directory (ie hadoop.tmp.dir) from the default /mnt/hadoop update the [plugin] section above with:
[plugin hadoop]
setup_class = starcluster.plugins.hadoop.Hadoop
hadoop_tmpdir = /path/to/hadoop/temp
This plugin creates a custom mapred-site.xml file for each node that, among other things, configures the mapred.tasktracker.{map,reduce}.tasks.maximum parameters based upon the node’s CPU count. The plugin uses a simple heuristic (similar to the one used in Amazon’s Elastic Map Reduce hadoop configs) that assigns 1 map per CPU and ~1/3 reduce per CPU by default in order to use all CPUs available on each node. You can tune these ratios by updating the [plugin] section above with the following settings:
[plugin hadoop]
setup_class = starcluster.plugins.hadoop.Hadoop
map_to_proc_ratio = 1.0
reduce_to_proc_ratio = 0.3
The Hadoop plugin will launch two web-based interfaces that you can access via your web browser. These web interfaces give you real-time stats for the Hadoop job tracker and namenode. The urls for the job tracker and namenode are given at the end of the output of the plugin:
>>> Job tracker status: http://ec2-XXXX.compute-1.amazonaws.com:50030
>>> Namenode status: http://ec2-XXXX.compute-1.amazonaws.com:50070
Here’s what the job tracker page should look like:
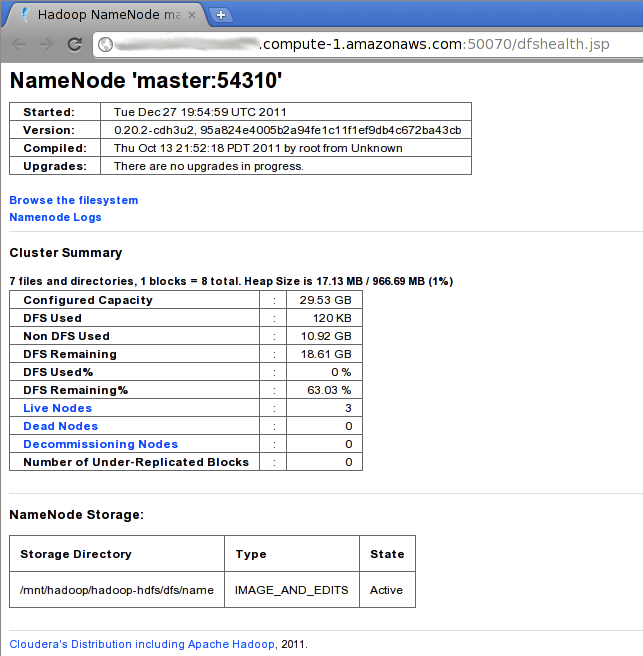
Here’s what the namenode page should look like
If you are familiar with the core Hadoop framework you should be able to get started quickly using the default Hadoop tool suite. However, if you’re a new user or if you’re tired of the verbosity of the core Hadoop framework, the Hadoop plugin also configures dumbo on your cluster. Dumbo provides a convenient Python API for writing MapReduce programs and in general makes things much easier when working with the Hadoop framework.
Note
Every dumbo command run must include the option -hadoop starcluster in order to run on the cluster using Hadoop/HDFS. Without this flag dumbo will run using the local environment instead of the Hadoop cluster.
You can quickly browse your Hadoop HDFS on any node using dumbo:
$ dumbo ls / -hadoop starcluster
To upload files to your Hadoop HDFS:
$ dumbo put /path/to/file /HDFS/path -hadoop starcluster
If you’d rather quickly view a file or set of files on HDFS without downloading:
$ dumbo cat /HDFS/path/to/file/or/dir -hadoop starcluster
To copy files from your Hadoop HDFS:
$ dumbo get /HDFS/path/to/file /local/destination/path -hadoop starcluster
You can also remove files and directories from your Hadoop HDFS:
$ dumbo rm /HDFS/path/to/file/or/dir -hadoop starcluster
Writing Hadoop mappers and reducers with dumbo is very easy. Here’s an example for a simple word count:
def mapper(key, value):
for word in value.split():
yield word, 1
def reducer(key, values):
yield key, sum(values)
if __name__ == "__main__":
import dumbo
dumbo.run(mapper, reducer)
Let’s assume this is saved to $HOME/wordcount.py and we’re currently in the $HOME directory. To run this example we first upload a text file to HDFS:
$ dumbo put /path/to/a/textfile.txt in.txt -hadoop starcluster
Next we run the wordcount.py example using the in.txt file we just put on HDFS:
$ dumbo start wordcount.py -input in.txt -output out -hadoop starcluster
This will run the word count example using the streaming API and dump the results to a new out directory on HDFS. To view the results:
$ dumbo cat out/part* -hadoop starcluster
If you’d rather download the entire results directory instead:
$ dumbo get out out -hadoop starcluster
See also
Have a look at Dumbo’s documentation for more details